
Page 390 - Công nghệ kỹ thuật và công nghệ thông tin trong tiến trình công nghiệp hóa - hiện đại hóa Đồng bằng sông Cửu Long
P. 390
tích hợp với nhiều nguồn dữ liệu phổ biến, bao gồm HDFS, Flume, Kafka
và Twitter. Spark không có hệ thống dữ liệu phân tán riêng, do đó, người
dùng có thể kết hợp sử dụng các hệ thống dữ liệu khác như HDFS, HBase
và Cassandra.
Apache Kafka là một nền tảng tin nhắn truyền phát hiệu suất cao,
được giới thiệu lần đầu tiên vào năm 2011 để thu thập và phân phối khối
lượng lớn dữ liệu (Kreps et al., 2011). Kafka có tính phân tán và có thể mở
rộng, cung cấp các giao diện lập trình ứng dụng (API) tương tự như hệ
thống truyền tin nhắn để xử lý lượng dữ liệu khổng lồ trong thời gian thực.
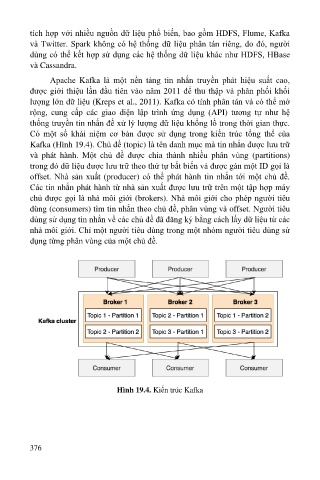
Có một số khái niệm cơ bản được sử dụng trong kiến trúc tổng thể của
Kafka (Hình 19.4). Chủ đề (topic) là tên danh mục mà tin nhắn được lưu trữ
và phát hành. Một chủ đề được chia thành nhiều phân vùng (partitions)
trong đó dữ liệu được lưu trữ theo thứ tự bất biến và được gán một ID gọi là
offset. Nhà sản xuất (producer) có thể phát hành tin nhắn tới một chủ đề.
Các tin nhắn phát hành từ nhà sản xuất được lưu trữ trên một tập hợp máy
chủ được gọi là nhà môi giới (brokers). Nhà môi giới cho phép người tiêu
dùng (consumers) tìm tin nhắn theo chủ đề, phân vùng và offset. Người tiêu
dùng sử dụng tin nhắn về các chủ đề đã đăng ký bằng cách lấy dữ liệu từ các
nhà môi giới. Chỉ một người tiêu dùng trong một nhóm người tiêu dùng sử
dụng từng phân vùng của một chủ đề.
Hình 19.4. Kiến trúc Kafka
376