
Page 396 - Công nghệ kỹ thuật và công nghệ thông tin trong tiến trình công nghiệp hóa - hiện đại hóa Đồng bằng sông Cửu Long
P. 396
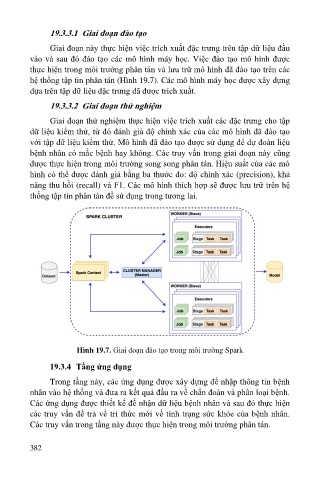
19.3.3.1 Giai đoạn đào tạo
Giai đoạn này thực hiện việc trích xuất đặc trưng trên tập dữ liệu đầu
vào và sau đó đào tạo các mô hình máy học. Việc đào tạo mô hình được
thực hiện trong môi trường phân tán và lưu trữ mô hình đã đào tạo trên các
hệ thống tập tin phân tán (Hình 19.7). Các mô hình máy học được xây dựng
dựa trên tập dữ liệu đặc trưng đã được trích xuất.
19.3.3.2 Giai đoạn thử nghiệm
Giai đoạn thử nghiệm thực hiện việc trích xuất các đặc trưng cho tập
dữ liệu kiểm thử, từ đó đánh giá độ chính xác của các mô hình đã đào tạo
với tập dữ liệu kiểm thử. Mô hình đã đào tạo được sử dụng để dự đoán liệu
bệnh nhân có mắc bệnh hay không. Các truy vấn trong giai đoạn này cũng
được thực hiện trong môi trường song song phân tán. Hiệu suất của các mô
hình có thể được đánh giá bằng ba thước đo: độ chính xác (precision), khả
năng thu hồi (recall) và F1. Các mô hình thích hợp sẽ được lưu trữ trên hệ
thống tập tin phân tán để sử dụng trong tương lai.
Hình 19.7. Giai đoạn đào tạo trong môi trường Spark
19.3.4 Tầng ứng dụng
Trong tầng này, các ứng dụng được xây dựng để nhập thông tin bệnh
nhân vào hệ thống và đưa ra kết quả đầu ra về chẩn đoán và phân loại bệnh.
Các ứng dụng được thiết kế để nhận dữ liệu bệnh nhân và sau đó thực hiện
các truy vấn để trả về tri thức mới về tình trạng sức khỏe của bệnh nhân.
Các truy vấn trong tầng này được thực hiện trong môi trường phân tán.
382